- Build Club
- Posts
- Build Club Banter: Introduction to RAG
Build Club Banter: Introduction to RAG
Introduction to RAG
Annie Liao, Navan Tirupathi, Isabelle De Backer, Jeng Yan Chia & Clinton Lui
March 18, 2024
Build Club Banter: Introduction to RAG

Banter time!
This article is brought to you by Build Club, the best place in the world to build in AI. We are top AI builders, shipping together. You can join us here
Contributors: Jeng Yan Chia, Isabelle De Backer, Navan Tirupathi, Clinton Lui
Join us, as we deep-dive into one of the hottest topics in AI at the moment RAG. In this comprehensive knowledge article we go through:
Table of Contents
Introduction
Large language models (LLMs) allow users to explore vast volumes of unstructured data like images, videos, audio, code and text using natural language queries. Despite leveraging extensive public data during training, there are instances where supplementary information, such as proprietary enterprise data, is indispensable for generating accurate responses.
We could just pass all those documents to a model inside the prompt but then models have a limited size of words they can process at once called a context window. Researchers have introduced a method called Retrieval-Augmented Generation (RAG) to tackle this challenge.
RAG is one of the easiest and most effective ways to give LLMs access to a particular dataset and useful in tasks where factual recall is important.
An easy analogy is an “open book” exam, rather than the model having to remember everything it was trained on it is allowed to look up information when answering questions. The origins of RAG trace back to as early as the 1970s, but the emergence of machine learning changed the usefulness and popularity of these techniques.
RAG comprises an initial retrieval phase where Language Model (LLMs) query external data sources to gather relevant information before responding to queries or generating text. Such data is first converted into embeddings to enable fast search. Embeddings are continuous vector representations of words or tokens that capture their semantic meanings in a high-dimensional space as numbers. This representation makes it possible to translate semantic similarity (measures how their meanings are close) as perceived by humans to proximity in a vector space. The additional information is then integrated into the prompts given to LLMs, offering context for the generation process. This way RAG works with any LLM. Embeddings are often stored in a vector or conventional database.
This approach not only informs subsequent text generation but also ensures that responses are grounded in retrieved evidence, thereby significantly enhancing accuracy and relevance.

Embeddings as multidimensional vectors [3]
Initially, in the RAG model proposed by Lewis et al. in 2020, the retrieval phase involved dense vector similarity search between the query and a knowledge store containing embeddings (described in naive RAG chapter below). The data is referred to as “bag of words” as embeddings represent unordered chunks of text. Today, vector search has advanced to query vector embeddings capable of storing language-independent and multimodal information, encompassing text, images, and videos across diverse subjects. In some instances, the retrieval process incorporates more sophisticated mechanisms such as knowledge graph queries, and is supplemented by keyword searches or other advanced techniques.
Use cases
The primary advantage of RAG lies in its ability to circumvent the need for retraining LLMs for specific tasks.
RAG plays a crucial role in avoiding llm knowledge cutoff in time and enhancing the accuracy of AI systems while mitigating hallucinations. Hallucinations are common when a model is made to answer questions beyond its training data —instances where AI generates outputs that are factually incorrect or nonsensical. RAG also enhances transparency in AI systems by revealing the sources of information utilised, fostering trust among users—an aspect challenging to achieve for training data. Due to improved awareness of the context, the output generated is more coherent and appropriate. This approach circumvents the limitation of relying solely on outdated training data or fabricated information, thus improving the quality of outputs.
Another advantage is adaptability to dynamic knowledge, resource efficiency and increased developer control. LLMs are normally “stuck” at a particular time, but RAG can bring them into the present. LLM-driven chatbots can provide customers with tailored responses without the need for humans involved in script creation. RAG ensures data updates do not require model updates and retraining. By simply adding the most recent documents or policies into the embeddings, the model is able to retrieve the latest information to address inquiries.
The benefits of RAG extend across various kinds of AI applications, including customer service chatbots, business intelligence and analysis, healthcare information systems, legal research, content creation, personalised recommendation systems and educational tools. Studies [1, 2] indicate a notable accuracy enhancement of two to five percent with proper implementation of RAG methodology.
Current state of RAG
Early retrieval techniques were devised to help model fine-tuning but it wasn’t before the advent of ChatGPT, that RAG was propelled to the forefront for its role in LLM inference, in this instance content generation from large language models. When RAG was introduced by Meta AI in 2020 [4] it combined an information retrieval component (Facebook AI’s dense-passage retrieval system [5]) with a seq2seq generator (at the time a Bidirectional and Auto-Regressive Transformers [BART] model). At the time, changing what a pre-trained language model knew entailed retraining the entire model with new documents (parametric knowledge). They saw its strength in the flexibility of the architecture: RAG enhances the accuracy and credibility of the models, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information.
The following figure summarises RAG architecture by depicting RAG based on dense vector search (from [6]).
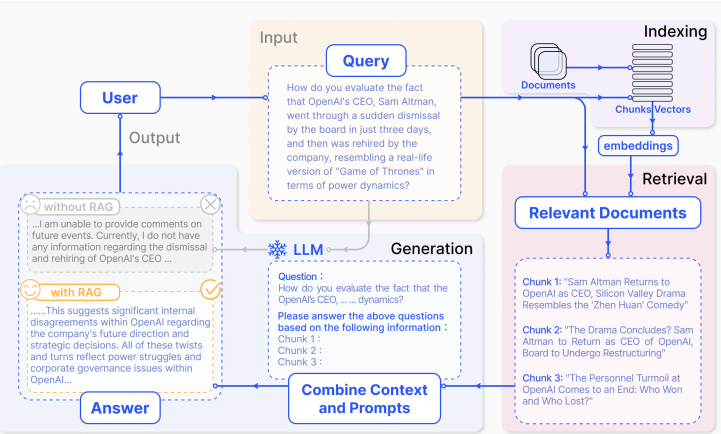
Today, RAG has evolved alongside foundational models, with a focus on tailoring retrieval techniques to enhance accuracy and recall of the model.
Naive RAG: Similarity search
Naive RAG represents the earliest methodology, which gained prominence shortly after the widespread adoption of ChatGPT in 2023 and involves a 3 steps process:
Indexing: this process occurs offline and involves extracting information from various unstructured sources such as PDF. Next are markdown, documents, segmenting it into chunks and storing those chunks as dense vectors in a vector database with an index for fast retrieval using Approximate Nearest Neighbours (ANN) techniques [9].
Retrieval: When receiving a user query, the query is embedded into a multidimensional dense vector using the same embedding model as the one used for the indexing phase. The vector database or index is requested to perform a similarity search (for example using cosine distance) between the query and the rest of the knowledge base, retrieving top k relevant vectors [4, 5, 6, 10].
Augmentation: Finally, the user query and retrieved text chunks (in plain text, not as vectors) are inserted into a prompt such as “Please answer the user query {query} using the following information {chunk1} {chunk2} {chunk3}”
Naive RAG can suffer from low recall (not retrieving all the relevant information) and/or low precision (not the right retrieved chunks). Various techniques have evolved to improve all aspects of naive RAG, the indexing, retrieval and augmentation.
Advanced RAG techniques
Pre-Retrieval
Query routing: Routing query to the right index for retrieval using a LLM, directing the query to various information store such as a vector store, a sql database or a graph database.
Query rewriting and expansion: the user’s original query may suffer from imprecise phrasing and lack of semantic information. Expanding the initial user query with additional pertinent context.
Indexing improvements
A few techniques aim at improving the quality of the unstructured data being indexed.
Enhancing data information quality: removing irrelevant text, outdated documents, removing ambiguities in entities and terms, etc…
Optimising indices structures: optimising chunk size to capture just the relevant context, enhancing retrieval by relating entities and related knowledge using a knowledge graph, querying multiple indices
Using metadata: Associating chunks with metadata to allow for filtering rules, dates or purpose, or event document hierarchies
Enhancing Semantic Representations to improve retrieval:
Chunk size optimization: embedding overly large or excessively small text chunks may lead to poor outcomes.
Small2Big is a technique that retrieves small text blocks initially but provides larger related text blocks to the language model for processing [6, 7].
Abstract embedding technique focuses first on retrieving the right document based on abstracts
Chunks related or enhanced by a knowledge graph is another semantic enhancing technique that deserves its own chapter.
Choice of embedding model: not all text embeddings are equal (see the Massive Text Embedding leaderboard (MTEB) on Hugging Face)
Fine-tuning Embedding
Domain Knowledge Fine-tuning. This involves customising embedding models to enhance retrieval relevance in domain-specific contexts using domain-specific datasets. For example LlamaIndex [9] offers tools and functionalities to streamline the fine-tuning process, making it more manageable.
Other Retrieval Techniques
Semantic retrieval can be enhanced or replaced by other retrieval techniques.
Hybrid search combines classic keyword search and vector search
Knowledge graphs can be used to link concepts and information
Post-Retrieval process
After retrieving valuable context from the vector store, it is essential to merge it with the query as an input to the LLMs while taking into account the context window size limit.
Re-ranking: This process involves a secondary triage in the list of chunks retrieved by the similarity search, and likely presented in order of similarity. For example, in LLM Rerank, an LLM can be prompted to give a relevancy score to each chunk based on the user query and also eliminate irrelevant chunks.
Prompt Compression: Research has highlighted that noise in retrieved document chunks adversely impacts the RAG performance. Prompt compression is about compressing retrieved chunks by highlighting relevant paragraphs, compressing irrelevant context.
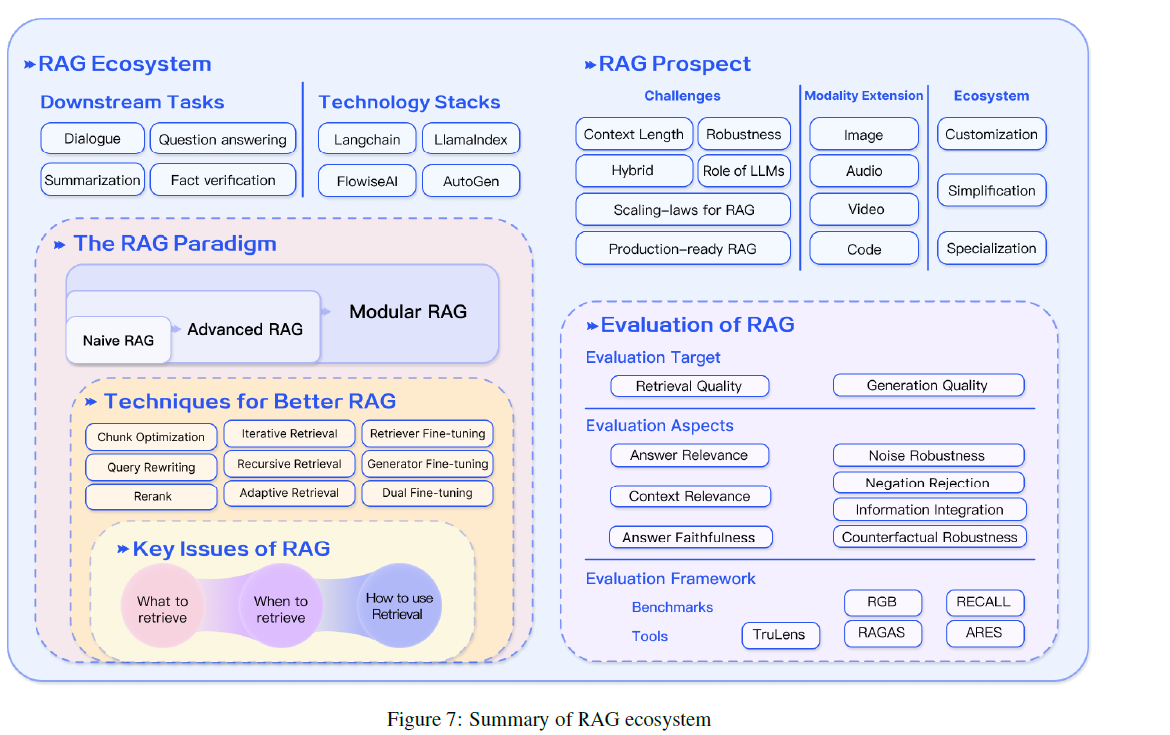
Using Knowledge Graphs: Case Study by WhyHow.ai
When LLMs consume a document, they have to guess the relationships between different entities and concepts mentioned. Sometimes they get things wrong because guessing is probabilistic and rely on semantic similarity.
As developers building in RAG have discovered, semantic similarity and relevancy are different things. This gets worse if models compound errors. They become more accurate when the relationships are more defined. Enterprises want more defined structure so it is easier to define your data. This is a huge important problem because we spent $100bn on AI infrastructure last year that needs an ROI. We use a technology called Knowledge Graphs to help define these relationships and rely on them in a deterministic manner.
There has been a growing consensus that graph-based frameworks are useful for more deterministic RAG systems. Microsoft has recently published about GraphRAG, McKinsey has talked about the necessity for enterprise knowledge graphs, and many other large enterprises have started adopting knowledge graphs within the context of LLM / RAG systems.
Broadly speaking, there are two ways to think about incorporating a graph. Knowledge graphs are not just data stores, they can also be reasoning structures.
Graph Representation
Knowledge graphs are conceptually simple things. They are a graph representation of knowledge. This graphical representation can represent the specific facts that you want to explicitly represent the connections between.
For example, in a legal use-case, it may be important to note that the definition of the word ‘Defendant’ is explicitly linked to ‘Person A’ to make sure that the LLM never hallucinates this fact when it is taking in this fact.
This representation does not need to simply be a concept. This representation may take the form of a document structure, or pages, or any other schema that it makes sense to organise and categorise your information with.
Graph Reasoning
Graphs may also be used as a means to help the LLM understand how to navigate information, instead of simply understanding how information is linked together. These are rules that help enforce what type of information should be retrieved in what order, for specific questions.
For example, we may want to make sure information is being manipulated in a specific decision tree, just like in a Customer Support SOP document, where if certain criteria are met, a specific information retrieval flow is required.
This is a clear distinction from storing all facts within the graph itself because how the information is retrieved matters almost more than what is in the graph in the first place.
When do you use each?
Graph Reasoning frameworks are utilised when there is a need to deterministically navigate information, inject context, or navigate chunk extraction. Frequently, the use-cases here are Look-Up focused, where the answer is known and we simply want to enforce determinism in the way that the LLM system is retrieving answers.
Graph Retrieval is helpful for augmenting additional context, especially around multi-hop use-cases. Frequently, the use-cases here are Search focused, where the answer is not fully known, and we simply want to make sure the LLM is adding additional relevant context for a more holistic answer, on the basis of explicit relationships mapped in the Knowledge Graph.
Common Myths
Common myths about adopting knowledge graphs around the amount of effort needed to create a fully perfectly described graph, typically reflect the traditional way that knowledge graphs have been used pre-LLMs.
However, with LLMs, the need for large graphs that perfectly describe all relationships and concepts are not necessary, as LLMs come with powerful semantic understanding of how the world works. It is only in the area of less-common knowledge, i.e. private company workflows and data-sets, that semantic structure needs to be imposed. Put in other words, graphs should be used to supplement LLMs and reduce uncertainty where semantic structure has to be ‘guessed’ by the LLM. Furthermore, LLMs themselves can be used as a tool to support and dramatically accelerate human development of graphs.
“Mini-Knowledge Graphs” are increasingly being used to help create structure for specific use-cases, and are sufficient to be relied upon, given that the historical need to describe a precise, all-encompassing world view has disappeared.
At WhyHow.AI, we are working on tooling for both Graph representation of your unstructured data, as well as deterministic engines for information retrieval through Graph Reasoning engines. If you are looking for deterministic and graph tooling for your RAG pipeline, hit the team up at WhyHow.AI or at [email protected].
Enterprise RAG Considerations
While building a RAG is relatively straightforward, making it robust and a reliable application in production often requires several considerations to improve the robustness and efficiency of the RAG system. Afterall RAG is more than just embedding search.
The following are different high level categories of various considerations
Functional considerations - End to End RAG Process and its failure points
Non Functional Considerations - Performance, Latency, Security, Operational Efficiency, Evaluation and Observability
Technology Choices -Tools, Deployment and Integrations
Functional considerations
Making the RAG robust requires validation of different failure points in the RAG process and establishing controls and putting guard rails in place at different steps
Through various case studies, there are seven key failure points as depicted in the below picture [17]:
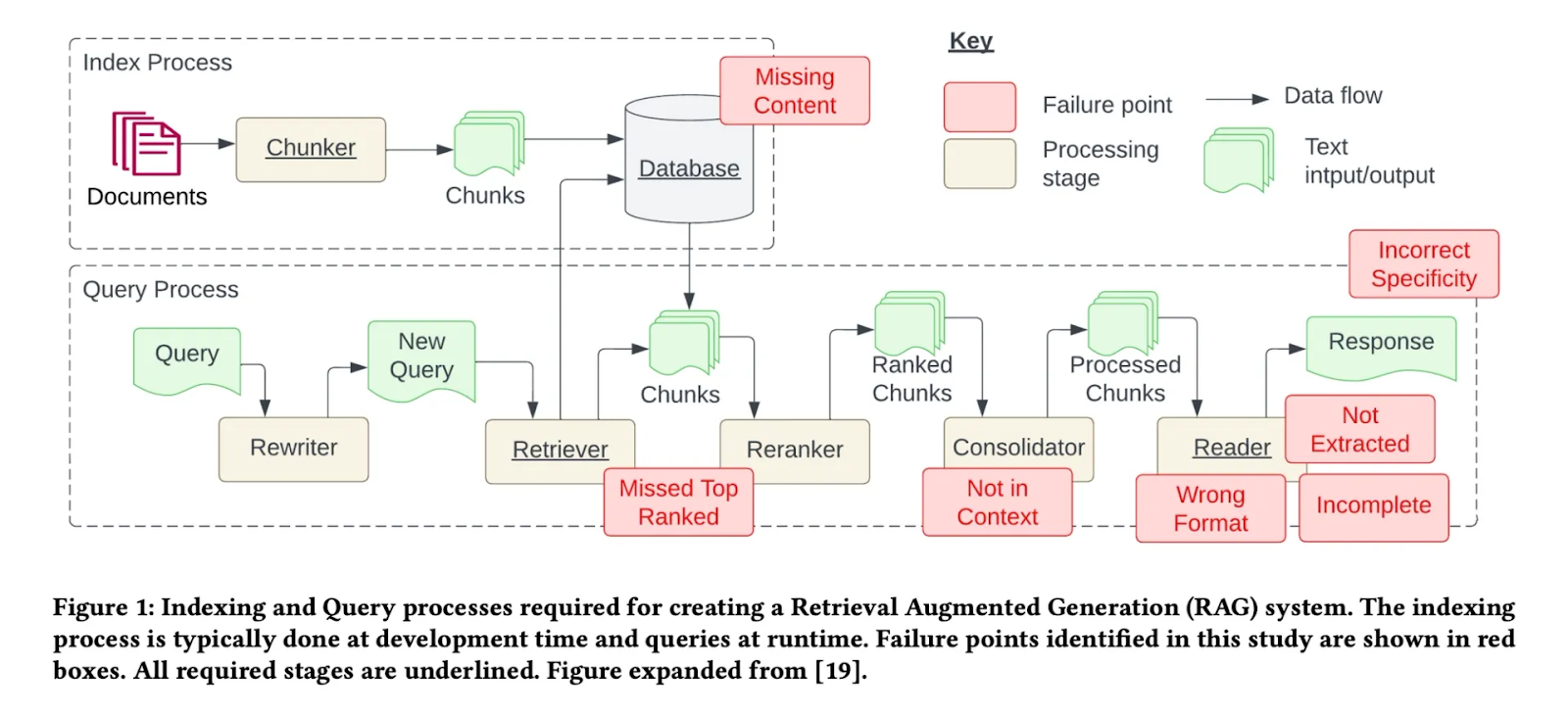
Missing content (FP1):
A question is posed that cannot be answered with the available documents. In the ideal scenario, the RAG system responds with a message like "Sorry, I don’t know." However, for questions related to content without clear answers, the system might be misled into providing a response.
Missed the top ranked documents (FP2)
The answer to a question is present in the document, but did not rank highly enough to be included in the results returned to the user. While all documents are theoretically ranked and utilised in subsequent steps, in practice only the top K documents are returned, with K being a value selected based on performance.
Not in context - consolidation strategy limitations (FP3)
Documents containing the answer are retrieved from the database but fail to make it into the context for generating a response. This occurs when a substantial number of documents are returned, leading to a consolidation process where the relevant answer retrieval is hindered.
Not extracted (FP4)
The answer is present in the context, but the model fails to extract the correct information. This typically happens when there is excessive noise or conflicting information in the context.
Wrong format (FP5)
The question involves extracting information in a specific format, such as a table or list, and the model disregards the instruction.
Incorrect specificity (FP6)
The response includes the answer but lacks the required specificity or is overly specific, failing to address the user’s needs.
Incomplete (FP7)
Incomplete answers are accurate but lack some information, even though that information was present in the context and available for extraction.
As part of solving certain use cases, there are lessons they learned from solving each problem [17] , we should keep this in the considerations while architecting the RAG system for enterprise
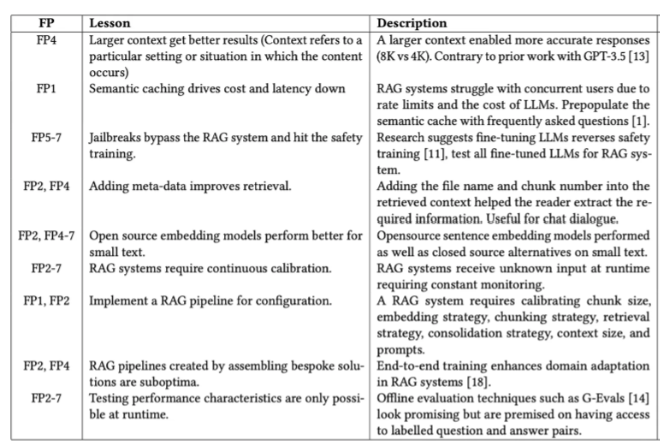
Based on this below are some of the Functional considerations to be applied
Document Ingestion Handling
When deploying RAG, consider the diversity and format of documents to be ingested, ensuring the system can handle various types of data efficiently. It's crucial to establish robust preprocessing pipelines to clean and standardise data, facilitating smoother integration and retrieval.
Chunking Strategies
Effective chunking strategies are essential for breaking down large documents into manageable, contextually relevant pieces. This improves the model's ability to retrieve and generate accurate information, enhancing the overall performance and user experience.
Encoding
Selecting the right encoding methods is critical for transforming text into a format that's understandable by the model. Consider the balance between computational efficiency and the richness of the encoded information to optimise both speed and accuracy.
Indexing Techniques
Indexing techniques must be carefully chosen to ensure quick and precise retrieval of information. The choice between dense and sparse indexing, or a hybrid approach, should be guided by the specific needs of your application and the characteristics of your data.
Storage
Storage solutions should not only be scalable but also optimised for fast access and retrieval times. Consider the trade-offs between storing in a Document store vs Vector store based on your latency cost and deployment considerations.
Query Handling
Developing sophisticated query handling mechanisms is vital to interpret and route user queries effectively. This includes understanding the intent behind queries and ensuring they can be matched with relevant documents or information pieces.
Input Guardrails
Implement input guardrails to manage the quality and type of queries fed into the RAG system. This helps in preventing irrelevant or inappropriate queries from affecting the system's performance and output quality.
Query Rewriting
Query rewriting techniques can significantly enhance the retrieval process by transforming user queries into more effective forms. This requires a deep understanding of the domain and the common information needs of the users.
Retrieval
The retrieval component should be fine-tuned to balance between recall and precision, ensuring that the system retrieves the most relevant information without overwhelming the user with unnecessary data.
Prompt-Assisted Generation
Leverage prompt-assisted generation to guide the RAG model in generating responses that are not only relevant but also contextually appropriate and coherent. This involves designing prompts that effectively communicate the task at hand to the model.
Output Guardrails
Establish output guardrails to ensure that the information generated by the RAG system is accurate, relevant, and free from biases. This is crucial for maintaining the trustworthiness and reliability of the system.
User Feedback Handling
Incorporate mechanisms for capturing and analysing user feedback to continuously refine and improve the RAG system. This feedback loop is essential for adapting to users' evolving needs and enhancing the overall effectiveness of the system.
Non Functional Considerations
Below are some of the Non Functional considerations while adopting RAG
Performance
How does the retrieval component's performance impact overall system latency and user experience?
Can caching strategies effectively reduce retrieval times while maintaining data freshness and relevance?
Security
What user authentication mechanisms ensure secure access without compromising ease of use?
How are data security, privacy, and compliance with regulatory standards guaranteed in the system's architecture and data handling practices?
Reliability
What measures are in place to ensure response reliability, especially under varying loads and data complexities?
How is the overall reliability of the RAG system maintained, considering the dependencies on external data sources and machine learning models?
Operational Efficiency
How can automation be leveraged to enhance operational efficiency, particularly in document store refreshes and model upgrades?
What strategies are employed for optimising the system's performance without compromising quality or increasing costs unduly?
Cost Effectiveness
How is storage cost-effectiveness achieved, especially considering the need for scalability and fast access times?
What are the trade-offs between retrieval speed and cost, and how can these be optimised for economic efficiency?
Monitoring and Evaluation
How is the observability of responses maintained to ensure issues can be quickly identified and addressed?
What mechanisms are in place for assessing answer relevance, context relevance, and the groundedness of the generated content?
For the Evaluation of RAG you validate three aspects in particular at minimum
Answer Relevance, Context Relevance and Groundness of your RAG system as illustrated blog from TrueLens [18]
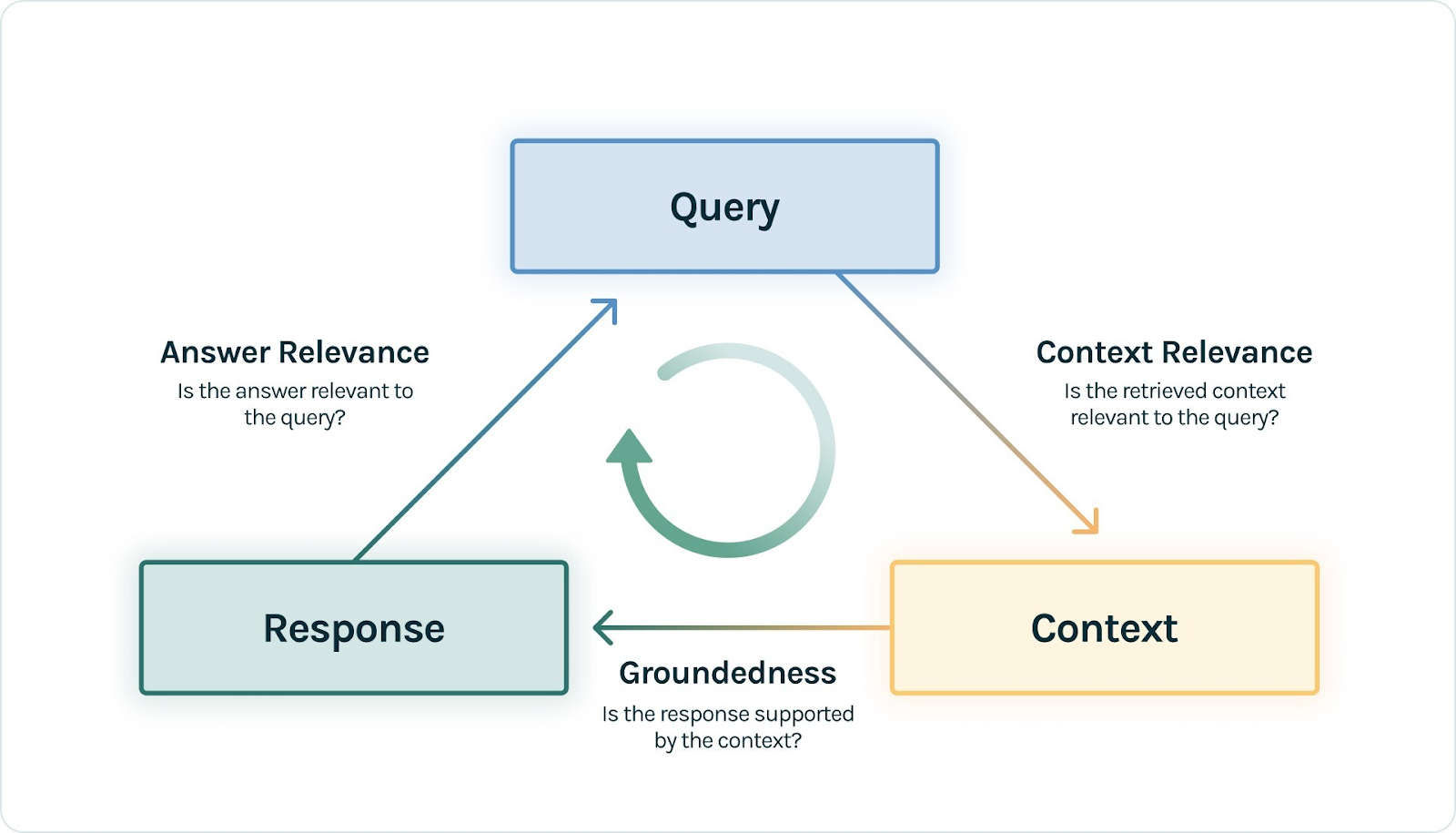
Technology Choice Considerations
Deployment
AWS, Azure,GCP, Databricks, Netlify etc
Embedding
Reference to https://huggingface.co/spaces/mteb/leaderboard for different models
Open AI - text embedding model
Vector Databases
Please refer to https://builder-club.beehiiv.com/p/build-club-banter-vector-db to find out which vector store will suit your environment
e.g: Chroma, Pinecone, Qdrant, Marqo, Milvus
Knowledge Graph
Neo4j, WhyHow.ai
Evaluation/Observability framework
Truelens
Ragas
Deepeval
Azure Phoenix
Langsmith
Toolsets and Integration
LlamaIndex, Langchain, Prompt Flow, Haystack
The future of RAG
RAG is currently the best-known tool for grounding (see “RAG triad” above) LLMs on the latest, verifiable information. Using RAG lowers the costs of having to constantly retrain and update models. Nevertheless, current public systems that are assumed to be using RAG like Bing and Bard (now Gemini) continue to be unreliable. Some people believe making RAG work reliably would be equivalent to solving Artificial general intelligence [12], which is still out of reach with today's technology.
While there have been lots of research effort around RAG systems, they have been mostly centred around text-based tasks. As models can handle multimodal data we need to extend modalities for a RAG system to support tackling problems in more domains such as code, image, audio and video.
There is also some discussion whether recent language models with very large context windows spell the “End of RAG” [13]. While using the additional data directly in prompt may replace RAG for use cases with smaller data sets, embeddings are still faster and cheaper today.
Jensen Huang, President of NVIDIA, expects focus for RAG to shift from retrieval to personalization over time [11]: In the future, computing is going to be more RAG-based. … The retrieval part of it will be less, and the personalised generation part will be much, much higher. … So I think we’re in the beginning of this retrieval-augmented, generative computing revolution, and generative AI is going to be integral to almost everything.
In a recent overview on the state of large language models (LLMs), Karpathy described LLMs as at the centre of a kind of operating system (see figure below). Just like computers have memory hardware and access to files, LLMs have a context window that can be loaded with information retrieved from numerous data sources [16].
Looking further into the future some people envision interconnected AI systems [15], with RAG at the heart of a collective intelligence network. RAG systems could autonomously interact with other AI systems, exchanging data and strategies. See [14] for more advanced ideas.
While improving RAG remains an area of ongoing experimentation and research there is broad consensus that it will be part of future chat and agent systems.
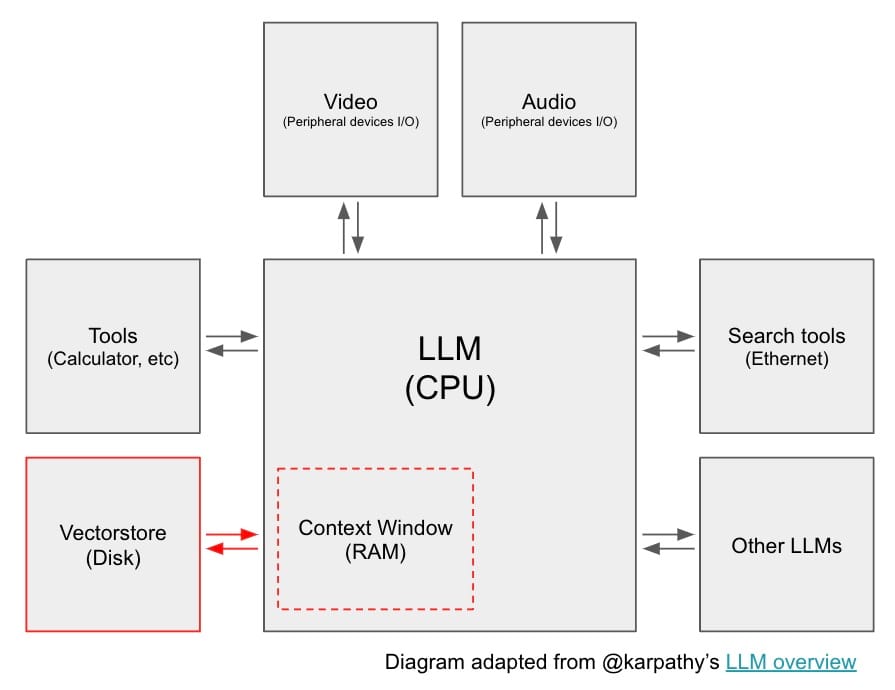
A LLM system with context window and vector store from [16]
Sources and links
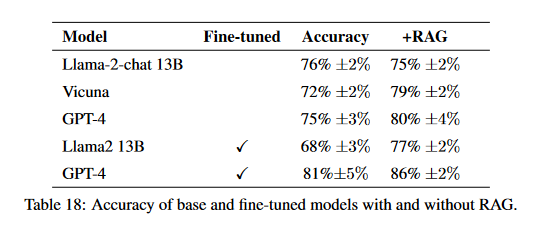
Angels Balaguer, Vinamra Benara, Renato Luiz de Freitas Cunha, et al., RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture, https://arxiv.org/abs/2401.08406,
Oded Ovadia, Menachem Brief, Moshik Mishaeli, and Oren Elisha ,Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs https://arxiv.org/pdf/2312.05934.pdf,
Ruhma Khawaja, Demystifying embeddings 101 – The foundation of large language models, accessed 5/4/2024, https://datasciencedojo.com/blog/embeddings-and-llm/
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474. Blog post: https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/ accessed 3/3/2024
Karpukhin, Vladimir, et al, Dense passage retrieval for open-domain question answering, arXiv preprint arXiv:2004.04906 (2020)
Gao, Yunfan, et al. Retrieval-augmented generation for large language models: A survey, arXiv preprint arXiv:2312.10997 (2023)
Yang Sophia, Small2Big technique using LlamaIndex https://towardsdatascience.com/advanced-rag-01-small-to-big-retrieval-172181b396d4, accessed 03-03-2024
Finetuning Embeddings (Llamaindex 2024) https://docs.llamaindex.ai/en/stable/optimizing/fine-tuning/fine-tuning.html#finetuning-embeddings, accessed 5/3/2024
Trabelsi, Eya,l 2020. Comprehensive Guide To Approximate Nearest Neighbors Algorithms, Medium, accessed 5/3/2024
Briggs, James, Semantic Search: Measuring Meaning From Jaccard to Bert, Pinecone, accessed 5/4/2024
Goode, Lauren, Nvidia Hardware Is Eating the World, https://www.wired.com/story/nvidia-hardware-is-eating-the-world-jensen-huang/, accessed 5/4/2024
Gary Marcus, No, RAG is probably not going to rescue the current situation, https://garymarcus.substack.com/p/no-rag-is-probably-not-going-to-rescue accessed 5/4/2024
Donato Riccio, The End of RAG? https://textgeneration.substack.com/p/the-end-of-rag, accessed 5/4/2024
Anupam Datta (TruEra/CMU) John Mitchell (Stanford) Ankur Taly (Google) , CS329T Trustworthy Machine Learning: Large Language Models & Applications Lecture 9, https://web.stanford.edu/class/cs329t/slides/lecture_9.pdf , accessed 5/4/2024
Deconstructing RAG, accessed 5/4/2024, https://blog.langchain.dev/deconstructing-rag/
Zach Blumenfeld and Enzo Htet, What Is Retrieval-Augmented Generation (RAG)? — Overcoming the Limitations of Fine-Tuning & Vector-Only RAG, https://neo4j.com/blog/what-is-rag/, accessed 5/4/2024
Pratik Bhavsa, Mastering RAG: How To Architect An Enterprise RAG System
https://www.rungalileo.io/blog/mastering-rag-how-to-architect-an-enterprise-rag-system, accessed 5/4/2024
The RAG Triad, https://www.trulens.org/trulens_eval/getting_started/core_concepts/rag_triad/, accessed 5/4/2024
P.S. Chatgpt has been used to rewrite some of this article.
Thanks so much for reading ❤️. Feel free to reach out to any of the contributors for further information - we are all in Build Club slack and socials!