- Build Club
- Posts
- Build Club Banter: Vector DB Part 1
Build Club Banter: Vector DB Part 1
Annie Liao
February 21, 2024
Part 1: Intro to and key considerations to choose a Vector DB

This article is brought to you by Build Club, the best place in the world to build in AI. We are top AI builders, shipping together. You can join us here
Contributors: Nissan Dookeran, Daniel Han, Isabelle De Backer, Annie Liao, Ali Haider Kachwalla, Daniel Bertram, Chris Rickard, Daniel Wirjo, Michael Misfud
Introduction:
What is a Vector Database?
In the rapidly evolving landscape of artificial intelligence, vector databases have emerged to manage and utilize vector embeddings. Vector embeddings are essentially compact representations of data points in a standardized machine readable format. Computers do not like processing images, text, and audio, but rather numbers, and vector embeddings enable machines to interpret and process these complex datasets. They can determine the similarity of 2 songs, fetch the “closest” book for example, or be used as a knowledge library like in Google Search. A vector database is designed to efficiently store, query, and manipulate these vector embeddings. But searching huge vector databases can be slow, so Approximate Nearest Neighbor (ANN) algorithms are used to retrieve similar vectors at the expense of some reduced accuracy.
This functionality is a key competitive area for vector databases, as they strive to outperform in terms of speed, accuracy, and relevance.
How do Vector DBs compare to other databases like SQL?

Specific use case of vector databases
Vector databases are used in applications where manipulation of those feature vectors is relevant (similarity, clustering, outliers…). In each use case, the way those vectors are created, a.k.a the embedding method is particularly relevant and needs to be considered separately to the use of the database itself.
Customer Segmentation and Profiling: In marketing and sales, customer data embeddings can help in segmenting customers based on behavior, preferences, or demographics, enabling targeted marketing strategies.
Natural Language Processing (NLP): For applications such as semantic search, chatbots, or document clustering, vector databases can store text embeddings. These embeddings capture semantic information from texts, enabling more nuanced and context-aware search and analysis. Vector databases are at the heart of Retrieval Augmented Generation (RAG) pipelines, which are used to retrieve relevant context for LLMs.
Anomaly and Fraud Detection: In financial services, embeddings of transactional data can be stored in vector databases to identify unusual patterns or anomalies, aiding in real-time fraud detection systems.
Recommendation Systems: In e-commerce, streaming services, or content platforms, vector databases can enhance recommendation engines. By storing user and item embeddings, these databases can quickly find items similar to a user's past preferences or items.
Biometric Identification: For applications like facial recognition or fingerprint identification, biometric data can be converted into embeddings and stored in vector databases for fast and accurate identity verification.
Voice Recognition and Processing: Vector databases can store embeddings from voice data, facilitating tasks like voice search, voice authentication, or sentiment analysis from spoken language.
Drug Discovery and Genomics:: Vector databases can be utilized in genomics research for DNA sequence analysis, variant calling, and genetic similarity comparisons. Vector databases can manage embeddings of molecular structures aiding in research like drug similarity analysis.
Time Series Analysis: Embeddings of time series data in fields like finance, weather forecasting, or IoT can be managed using vector databases for pattern recognition, anomaly detection, or predictive analytics.
"As a big fan of using embeddings to represent complex documents, old-school libraries such as ANNOY and FAISS have been at the heart of rapid comparison and search. Vector databases extend this ability to provide a robust and scalable platform to build upon." - Michael Misfud (Build Club Season 0)
Overview of Current Vector Database Vendors
Chatbot answering your questions about Vector DBs. Credit to Isabella De Backer for making this (Build Club)
Access it here

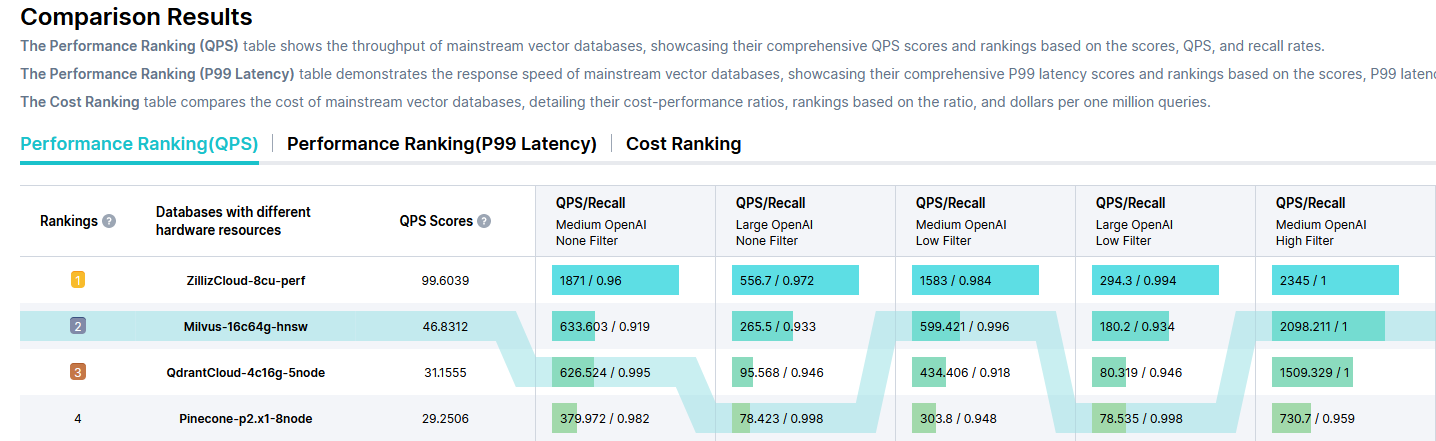
Benchmarks
Milvus introduced VectorDBBench, an open-source benchmarking tool, last year. This tool is vital for early evaluations of vector databases across different conditions. Unlike traditional evaluation methods, VectorDBBench assesses databases using real-world data, including super large datasets or those closely resembling data from actual embedding models, providing users with more insightful information for informed decision-making.
Access it here
Note: not all databases are represented in this benchmark.
ANN-Benchmarks is a benchmarking environment for approximate nearest neighbor algorithms search.
Finally, this website tests the streaming ingestion performance of Rockset and compares it to open-source search engine Elasticsearch, a popular sink for Apache Kafka
Choosing the Right Vector Database for Your Startup:
Open source Airtable here
Contribute or add changes here

Preview…
Use case: What is your use case and the tech stack that you are already using? It is likely that your current database offers vector search too.
Scalability: How do they scale with increasing amounts of data?
Most vector databases are built to handle large-scale datasets and can scale horizontally to accommodate growing data volumes. They distribute the storage and processing of vectors across multiple machines, enabling efficient handling of massive amounts of embedding data.
Reliability: suitability for production workloads
Query Speed: How fast is a similarity search ?
Vector databases employ advanced indexing structures and search algorithms, such as approximate nearest neighbor (ANN) algorithms, to achieve fast and accurate similarity searches. The different algorithms differ in their speed and accuracy.
Accuracy of the search results: of the similarity search algorithm (vs amount of data and speed)?
Type of data handled alongside vectors: Can they store the data alongside vectors? multimodal data as well?
Community and Framework support: Language and framework support (python, typescript ....), Community, documentation and support (how easy it is to find answer to one's problem). What libraries support that database? (e.g. is it included by default in llama_index, langchain etc...)
Type of implementation: where does the vector database reside : cloud, self-hosted, embedded (in-process vector db in memory or on disk)
Extra features? for example how to visualize your data etc...
Cost and License: Open source or proprietary? Free or not?
Evaluating Vendors
Making the Final Decision
Tradeoffs to consider
In the realm of vector database selection, data scientists and engineers must navigate a complex landscape of trade-offs and competing priorities.
Key considerations include:
Scalability vs Query Speed: Scaling up often means distributing data across nodes, resulting in network latency which affects query speed.
Search Precision vs Query Speed: High-precision search algorithms, like exact nearest neighbor search, are extremely slow, requiring more resources. Conversely, approximate algorithms might compromise on precision to decrease time and resource requirements.
Customizability vs Performance: Vector databases offering high customizability allow engineers to tailor systems to specific requirements. However, this flexibility can introduce overheads, affecting performance.
Data Durability vs Query Performance: Ensuring data longevity and reliability often involves extra disk operations, which can slow down queries.
Storage Location vs Data Security: Choosing between local storage for faster access and cloud storage for scalability and redundancy.
Direct Library Access vs Abstraction: Some vector databases offer direct library interfaces for deeper system integration, while others provide higher-level abstractions for ease of use.
User-Friendliness vs Advanced Capabilities: Databases that are easy to use may lack certain advanced features and optimization techniques.
And that’s it! We hoped this article helped you understand and choose which vector database you might want to use!
Stay tuned for part 2 where we deep-dive into the world of embeddings.